
Project [Grey Matter Segmentation Algorithm from Brain MR images]
Grey Matter Segmentation Algorithm from Brain MR images
1. 추진배경 및 필요성
-
추진배경
기존 영상 분할에 사용되는 방법 중 하나는 임계값 처리(Thresholding)가 있음. 데이터의 분포를 확인하여 픽셀 값이 불연속인 지점을 찾은 후 임계 값 처리를하는 방식의 단점으로 뽑히는 대표적인 문제는 잡음(noise)임. 데이터에 잡음이 있으면 불연속인 지점을 찾는데 한계가 있고 잘못하면 잘못된 영상 분할을 함. 또한 딥러닝 알고리즘에 비해 기존 방식은 시간적으로 꽤 소요되는 문제가 생김. 특히 본 연구에서 사용된 T1 강조(T1-weighted) 자기공명영상은 최근 의료영상 기반 질환 진단, 예후예측등 인공지능 기술과 합쳐져 다양한 응용분야에서 뛰어난 성능을 발휘하고있음.
-
연구 목표
본 연구는 자기공명영상에서 회백질 영역을 분할하는 기존 영상분할작업을 딥러닝 알고리즘을 대체하여 정확도를 유지하면서도 처리 시간을 단축하고 기존 영상분할 작업의 문제점이였던 영상의 잡음 유무에 관계없이 영상 분할을 처리하고자 함.
- 각 자기공명 영상의 크기와 복셀 사이즈가 다르기에 Statistical Parametric Mapping(SPM) 패키지를 이용하여 영상 데이터의 크기를 표준뇌 참조 영상과 같아지도록 리슬라이스(reslice) 하여 강도 자르기(intensity cropping)을 시행함.
- 학습에 사용한 딥러닝 모델은 3D-ResUnet이며, 패치 기반(patch-based)으로 변형하여 학습함.
- 학습 모델의 평가는 1. Dice 계수와 2. Intersection over union(IOU)를 이용함.
2. 연구 결과
-
데이터 셋
본 연구에서 사용한 데이터는 알츠하이머 병 뇌 영상 데이터베이스(ADNI)로 부터 획득함.
ADNI 데이터셋에서 65명의 자기공명 영상을 사용하였으며 이 중 50명의 환자 영상을 훈련 데이터로, 10명 환자 영상을 검증 데이터로, 나머지 5명을 테스트 데이터로 설정하고 학습 및 실험을 진행함.
-
데이터 전처리
각 영상의 크기는 영상획득 프로토콜에 따라 조금씩 다름.
딥러닝 모델에 넣어주기 위해 SPM패키지를 이용하여 모든 영상의 크기를 표준뇌 참조 영상과 같아지도록 Reslice하여 준비함. (표준뇌 영상 크기: 복셀 사이즈 1 x 1 x 1 mm3, 크기 256 x 256 x 256)
Reslice를 거친 영상은 대부분의 강도 값들이 0 근처에 모여있지만, 일부 강도 값이 매우 큰 복셀이 나타남. 강도의 히스토그램 분석을 통해 상위 99% 이상은 99%의 값으로 처리하는 강도 자르기를 시행하여 범위를 제한함[그림 1].

[그림 1] 특정 이미지의 (a) 원래 이미지의 복셀 값 범위, (b) 강도 자르기를 실시하여 보정한 이미지의 복셀 값 범위
자기공명 영상에 대한 회백질(gray matter) 마스크는 SPM 패키지의 영상분할 작업을 시행하여 획득하였고, FSL tool을 이용하여 이진 마스크로 구성함.

[그림 2] 데이터 전처리 전체 흐름도
-
딥러닝 모델, 3D-ResUnet
본 연구에서는 3D-ResUnet 모델을 패치 기반(patch-based)으로 변형하여 사용함.
Unet은 입력과 출력 사이의 매핑을 학습하는 딥러닝 모델이며, 인코더와 디코더 사이에 추가 파라미터 없이 연결되는 스킵연결(skip connection)이 있음. 스킵연결은 디코딩 과정에서 인코딩 과정에서 만들어진 특성맵을 활용하여 더 높은 선예도를 획득할 수 있도록 도와줌. 일반적으로 학습 효과를 높이기 위해선 딥러닝 네트워크를 깊게 쌓아야 하는데, 층이 깊어질수록 그래디언트 소실 현상이 심해져서 학습을 방해할 수 있음. 잔여블록을 이용하면 이러한 학습을 가속화할 수 있을 뿐 아니라, 과적합을 피할 수 있음. 잔여블록은 입력 값을 출력 값에 더해주는 지름길연결(shortcut connection)을 하나 만들어주는 것임.
본 연구에서 사용한 3D-ResUnet은 3차원 합성곱신경망을 사용하는 Unet인 동시에, 잔여블록을 활용하여 성능을 개선한 모델이다.

[그림 3] 3D-ResUnet의 구조 도식화

[그림 4] 패치 기반 학습
(50, 256, 256, 256, 1) -> (400, 128, 128, 128, 1) : Train patch data shape
(10, 256, 256, 256, 1) -> (80, 128, 128, 128, 1) : Validation patch data shape
(5, 256, 256, 256, 1) -> (40, 128, 128, 128, 1) : Test patch data shape -
학습 방법 및 정량적 평가 방법
자기공명 영상을 입력 데이터로 사용하였고,회백질 이진 마스크는 정답 데이터로 사용하여 학습을 진행함.첫번째로 다이스 계수(Dice coefficient)를 손실함수로 사용하여, 입력 데이터에서 정답 데이터로 학습하도록 함. 두번째로 사용한 함수는 Intersection over union(IOU)를 사용하여, 다이스 계수와 IOU 측정치에 대한 비교를 진행함. 패치를 이용하여 한 사람의 영상을 8개의 패치로 나누고, 미니배치의 크기(batch size)를 2로 하였으며, 총 500번의 에폭(epoch)동안 학습을 진행함. 최적화 알고리즘은 Adam을 사용함.
모든 구현은 유닉스 상(Ubuntu 18.04.5 LTS)의 Python 버전 3.8.8에서 구글 텐서플로우 (TensorFlowTM) 버전 2.5.0, 케라스(Keras) 버전 2.5.0으로 구현되었다. 학습에 사용된 하드웨어 정보는 다음과 같다 (CPU: Intel i7-6700@3.4GHz, GPU: Nvidia RTX 3090 24GB, memory: 48GB).
모델의 평가 방법은 손실함수로 사용했던 다이스 계수와 IOU를 이용함.
-
연구 결과
그림 5는 최종 모델의 학습 곡선을 보여줌. 과적합을 막기 위해 검증데이터에서의 손실이 더 이상 증가하지않는 정도에서 학습을 멈추었음.
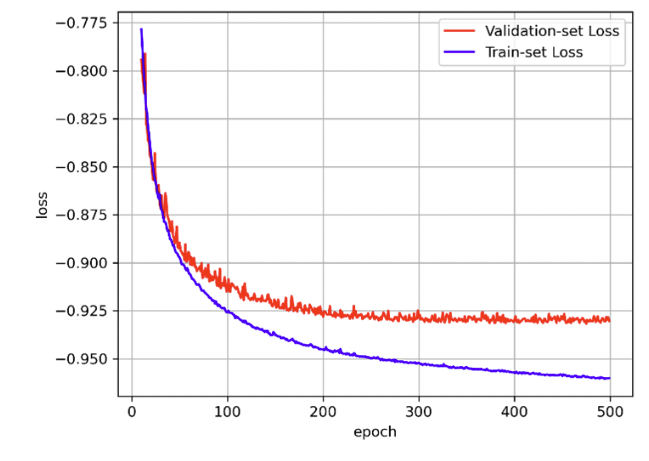
[그림 5] ADNI 데이터에 대해 3D-ResUnet의 학습 및 검증 손실 그래프


[그림 6] 테스트 데이터에서의 모델 처리 결과 예시
그림 6은 ADNI 테스트 데이터 첫번째 영상을 예시로 그린 것임. 입력 영상은 자기공명 영상을 보여주고, 정답 영상은 자기공명 영상으로부터 회백질을 분할한 영상임. 보라색 박스를 보면 정답 영상보다 3D-ResUnet에서 뇌 경계가 더 얇고 뚜렷하게 보이는 것을 확인할 수 있음. 이는 기존 영상 분할 작업보다 더욱 뇌 사이의 경계를 선명하게 분할하는 것이라고 생각됨. 3D-ResUnet의 결과는 정답 영상과 시각적으로 유사하게 나왔으나 테스트 데이터 5명에 대한 평균 IOU의 점수는 0.8406, 다이스의 점수는 0.9136이 나왔음.
3. 결론 및 향후 연구 방향
-
결론
본 연구에서는 영상분할 작업을 딥러닝 알고리즘(3D-ResUnet)으로 학습하는 연구를 진행함. 시각적 비교 결과, 정답 영상과 예측 영상이 거의 유사했으나 정량적 평과 결과 기존 과정의 정확도보다 낮게 나옴. 예측 시 영상 배경에 잡음이 생기게 되는데(그림 7), 이는 정확도를 검사할 때 점수를 낮게 만드는 요인 중 하나라고 생각 됨. 추 후 예측 영상을 후처리 과정을 통해 배경 잡음을 제거하면 기존 결과보다 더 뛰어난 성능이 나올 것이라 생각 됨.

[그림 7] 예측 영상의 배경 잡음
-
연구 방향
학습에 사용한 데이터가 50명이라서 데이터가 부족한 경향이 있음. 그래픽 카드 메모리의 한계로 인해 모델의 파라미터를 낮게 설정했기 때문에 점수가 낮게 나왔을 것임. 추 후, 예측 영상의 잡음을 제거하고 학습에 필요한 데이터들을 충분히 모으고 여러 장의 그래픽 카드를 활용하여 메모리를 분산한다면 기존결과보다 더 뛰어난 결과가 나올 것이라 생각됨.
4. 연구결과 활용
- 영상분할 작업은 컴퓨터 비전에 아주 중요한 기술이고, 해당 모델을 통해 많은 양의 영상들의 처리시간을 줄여 여러 의료 연구의 가속화를 할 수 있을 것이라 기대됨.
댓글남기기