
goormNLP [Demensionality Reduction]
Auspice by Goorm, Manage by DAVIAN @ KAIST
Lecture: Demensionality Reduction
2022-02-07
황금같은 설 연휴가 지나고 수업도 다시 재개되었다..
지난시간에는 Dimension Reduction을 통해 특정 Feature를 선택하거나 추출하는 기법 중 하나인 PCA에 대한 수업을 진행하였다.
이번엔 Multidimensional Scaling (MDS)에 대한 내용을 리뷰하겠다.
리뷰에 들어가기에 앞서 왜 ? 고차원 데이터를 저차원 데이터로 변환하여 Visualizing하는지 말을 이어가겠다.
우리는 3차원 공간에서 살고 있으며, 보고 느낄 수 있는 것들은 1, 2, 3차원이다. 이것이 우리가 태생적으로 가지는 핸디캡이다.
하지만 머신러닝에서 다루는 차원의 수는 매우 크다. 저번 HW14 리뷰를 기억해보면 무려 10,000개가 넘는 차원을 가지고 있었다.
그러하여 고차원 공간을 우리가 이해할 수 있는 저차원 공간으로 변환하는 기술을 연구하였고 이를 Dimensionality reduction이라 한다.
Multidimensional Scaling (MDS)
-
Main idea Tries to preserve given pairwise distances in low-dimensional space.

- Metric MDS Preserves given distance values
- Nonmetric MDS When you only know/care about ordering of distances Preserves only the orderings of distance values.
-
Algorithm: gradient-decent type.
MDS - Sammon’s mapping.
- Sammon’s mapping

- Local version of MDS
- Down-weights errors in large distances.
- Algorithm: gradient-decent type.
Practice
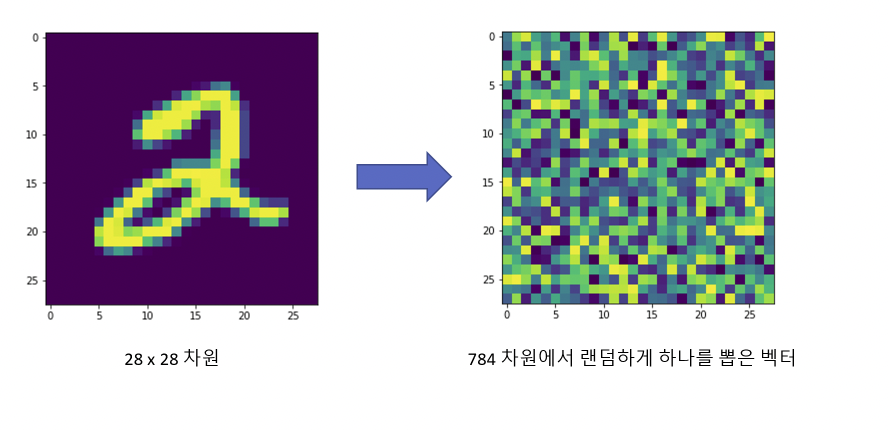
- MNIST는 가장 간단한 이미지 데이터셋이며, 28 x 28 pixel의 숫자 이미지로 구성되어 있다.
-
각각의 이미지는 28 x 28 pixel들을 가지고 있기 때문에 관찰자는 28 x 28 = 784 차원의 벡터를 확인할 수 있다.
하지만 784 차원은 매우 많은 벡터들이 존재하고 MNIST가 차지하는 공간은 매우 작다. -
수 많은 이미지들 중에 숫자를 나타내는 이미지는 매우 드물고, 그렇기 때문에 차지하는 차원도 더 작을 것이다.
이 매우 드문 것들을 더 작은 차원으로 내리려는 노력을 하기 위해 수업 때 배운 PCA 방법을 사용할 것이다.
step 1) 42,000개의 데이터 중 15,000개를 가지고 진행 함.
step 2) feature의 개수가 매우 많아 scikit-learn의 StandardScaler를 이용하여 z-score 정규화를 진행 함.
step 3) scikit-learn의 PCA 패키지를 사용하여 확인한 결과:
from sklearn import decomposition
pca = decomposition.PCA()
pca.n_components = 2
pca_data = pca.fit_transform(sample_data)

- 784차원에서 PCA를 통해 2차원으로 줄어든 것을 확인할 수 있음.
댓글남기기